In the pharmaceutical industry, regulatory documentation may need to be produced and maintained in multiple languages throughout various phases of the product lifecycle — from early-stage drug development through to post-marketing surveillance. This is particularly relevant in Europe, where medicinal products are authorised across multiple countries, requiring documentation to be available in up to 26 official EEA languages. To manage these demands and accelerate turnaround times, some life science companies are exploring the use of artificial intelligence (AI) to support translation processes. AI-powered tools promise to generate documents in the required language quickly and cost-effectively. Yet in such high-risk contexts, AI-generated translation raises significant concerns.
This article examines the growing interest in AI-powered translation in the pharmaceutical industry, the risks it presents when applied to regulatory documentation, and why human expertise remains essential to ensure accuracy, accountability, and traceability.
AI-Powered Tools and Their Appeal in Pharmaceutical Regulatory Translation
Pharmaceutical companies facing mounting documentation requirements are increasingly tempted by GenAI tools that promise faster, scalable workflows. Among the most prominent technologies are Large Language Models (LLMs) and Neural Machine Translation (NMT) — both advanced applications of natural language processing (NLP), with distinct strengths and limitations when used for regulatory translation in the pharmaceutical sector.
Large Language Models
LLMs, such as GPT-4, Claude, and Gemini, are not purpose-built for translation but for general language generation. Trained on massive monolingual and multilingual corpora, these models can simulate translation tasks across hundreds of languages when prompted effectively. Their appeal lies in their flexibility and contextual sensitivity: with the right inputs, LLMs can adapt tone, register, and even domain-specific phrasing. They are also easily available to the general public, rather than being limited to language-industry professionals.
A recent study published in The Lancet Digital Health found that GPT-4 achieved 79% agreement with physicians across 784 question–response items in medical notes written in English, Spanish, and Italian — demonstrating its strong multilingual medical reasoning capabilities.
Neural Machine Translation
NMT systems are trained on large volumes of parallel texts in two languages. Using encoder–decoder architectures and neural networks, NMT can produce full-sentence translations with impressive fluency, far outperforming earlier statistical machine translation (SMT) methods, such as the infamous Google Translate. Because NMT analyses sentences holistically — rather than word by word — it can often produce smooth, human-like output for predictable, structured content. These systems are already embedded into many translation management environments, such as RWS Studio, and can churn through thousands of words in minutes, making them very compelling for time-sensitive documentation, such as pharmacovigilance case narratives, internal reports, or medical literature.
From a productivity standpoint, the appeal is clear. An NMT engine can generate translations of a 50-page Summary of Product Characteristics into 25 EEA languages in a matter of minutes — a task that normally requires multiple linguists and several weeks of coordination. These efficiency gains make AI-driven translation extremely attractive in the current landscape where documentation volumes and deadlines continue to accelerate. To date, there are no publicly available, peer-reviewed studies that demonstrate the power of NMT alone for cross-language regulatory documentation in pharmaceuticals — and there is a very good reason for that. As the next section explores, fluency does not equal accuracy, and regulatory compliance cannot be assumed without accountability and traceability.
Challenges of Using Stand-Alone AI-Generated Translation in Regulatory Submissions
Accuracy Limitations in European Languages Other than English
Both NMT and LLM systems rely on the volume and quality of the data they are trained on — yet publicly available multilingual corpora remain overwhelmingly English-centric. According to the latest Common Crawl language report (June 2025), 45.27% of web content is in English, while major EEA languages, such as German, French, and Spanish, each account for just under 6%. Other official EEA languages, such as Icelandic and Maltese, are barely represented in digital corpora, making up only 0.0367% and 0.0033% of web content, respectively.
A peer-reviewed Nature study published in 2024, which evaluated 55 translation directions, explicitly states that, when using NMT systems, translation into English is systematically easier than translation out of English. The quality gap is particularly pronounced for languages with rich morphology and limited digital resources, the latter a direct consequence of data imbalance. This asymmetry highlights the tangible risks to accuracy when relying solely on AI to translate from English into other EEA languages, particularly those that are both digitally underrepresented and morphologically complex.
Document Formats and Layout Complexity
Pharmaceutical regulatory documentation often comes in a variety of formats, many of which are not readily editable. CMC (Chemistry, Manufacturing, and Controls) documentation, in particular, is frequently shared as scanned PDFs containing multi-level tables, chemical formulas, handwritten notes, wet ink signatures, and stamps — all of which must be preserved with precision.
AI-based translation tools, even those integrated into professional translation environments, struggle to interpret such complex layouts. This often results in distorted formatting or missing content during machine processing. In such cases, manual pre-formatting and post-processing are essential — tasks that can account for as much as 25% of the total project lifecycle.
Context Gap in Abbreviations and Itemised Lists
Pharmaceutical regulatory documentation is written for a highly specialised audience, often with the assumption of prior knowledge. As a result, sentences may be fragmented, densely packed with internal references, and filled with abbreviations that are domain-specific and rarely explained. These texts frequently include lists where minimal context is provided, as the intended meaning is considered self-evident to the expert reader.
Acronyms, such as BRR (Batch Record Review) or FP (Finished Product), appear across all EEA languages and often carry highly specific meanings within a regulatory context. With limited linguistic context and no embedded domain or procedural knowledge, AI technologies frequently mistranslate, omit, or even invent expansions for such abbreviations — leading to potentially serious accuracy issues. Similar risks arise with low-context terms in list entries: for instance, the word lake is often misinterpreted as a body of water rather than a colouring agent in a list of excipients. Only a human translator with subject-matter expertise, procedural familiarity, and access to supporting documentation from previous submissions can reliably interpret such terms. This contextual awareness is essential to ensuring both accuracy and consistency across the product dossier.
Official Templates and Regulated Terminology
A number of regulatory documents must follow official templates — such as the European Medicines Agency’s Quality Review of Documents (QRD) templates used for Summary of Product Characteristics (SmPCs), labelling, Patient Information Leaflets (PILs), and Periodic Safety Update Reports (PSURs). These templates are highly structured and contain prescribed wording, ordering, and writing conventions that must be strictly followed. They are available in all 26 official EEA languages and are mandatory for products authorised via the Centralised, Decentralised, and Mutual Recognition Procedures. Veterinary pharmaceuticals authorised under those procedures are subject to similar rules.
In addition, exact translation is required for regulated terminology. Excipient information on the labelling and package leaflet must follow the wording specified in the European Commission guidelines. Terms for pharmaceutical dose forms, routes and methods of administration, and packaging types must align with EDQM Standard Terms. Similarly, System Organ Classes (SOCs) as well as adverse reactions and their frequencies must reflect validated terminology from the Medical Dictionary for Regulatory Activities (MedDRA).
AI-based solutions, when used in isolation, are unable to navigate such regulatory constraints. Without appropriate terminology enforcement and template-specific guidance, they are likely to deviate from required phrasings or generate inconsistent or non-compliant terms.
Recognising these risks, EMA states in its Reflection Paper on the Use of AI in the Medicinal Product Lifecycle (September 2024) that AI and machine learning (ML) applications used for translating medicinal product information documents should be used under close human supervision. The paper also stresses that, because generative models can produce plausible but incorrect or incomplete output, robust quality review mechanisms must be in place to ensure that model-generated text is both syntactically and factually accurate before being submitted for regulatory review.
Terminology Management and Consistency
Efficient translation demands terminological precision and conceptual consistency across a range of documents and regulatory cycles. Maintaining this level of consistency across multiple languages requires structured terminology management, including controlled glossaries, translation memory (TM) tools, and robust version-control protocols.
Without integration into a broader, human-led ecosystem — involving professional terminologists and QA reviewers — AI-driven translation tools cannot reliably ensure consistent application of validated terminology.
A 2024 peer-reviewed study in AI‑Linguistica, which analysed NMT output for WHO public health documents in English, French, and Spanish, found that deviation from standardised WHO terminology accounted for 16% of all errors, while inconsistent use of terminology contributed to a further 9%. These were the second and third most frequent error categories after general mistranslations (19%). When one in four errors stems from terminology management issues, this presents a serious risk for pharmaceutical regulatory documentation, which is often characterised by high levels of repetition.
Data Protection and Information Security
Pharmaceutical regulatory documentation often contains confidential and commercially sensitive data. For example, correspondence with national regulators may disclose compliance issues, product deficiencies, or strategic decisions. Using cloud-based AI tools to translate such material poses significant information security risks.
Public LLMs and NMT engines may retain user-submitted content. In the free version of ChatGPT, inputs may be stored for up to 30 days and can be used to improve the model. Similarly, the free version of DeepL temporarily retains text to facilitate translation, though its retention policies are not fully transparent. Only DeepL Pro guarantees that input texts are not stored or reused, with all content deleted immediately after processing. While ChatGPT’s Business and Enterprise plans offer a Zero Data Retention (ZDR) setting — ensuring content is neither stored nor used for training — this feature must be explicitly activated and is only available on selected paid tiers.
There is already visible caution within the pharmaceutical sector. A 2023 peer survey of over 200 life sciences professionals, conducted by ZoomRx, found that 65% of the world’s top 20 pharmaceutical companies had formally banned the use of ChatGPT in the workplace. The most commonly cited concern was the risk of inadvertently disclosing sensitive or proprietary information.
ISO 17100 Certified, Human-Led Workflow
For pharmaceutical companies working with ISO-certified language service providers, translation services must follow a defined, human-led quality assurance workflow. ISO 17100:2015, the international standard for translation services, mandates that every project includes, at minimum, translation followed by full revision. Both stages must be performed by independent human linguists who meet specific qualification and experience requirements. Optional stages may include review (e.g. for specific subject domains) and proofreading (e.g. for printed material). A final quality check by yet another language professional ensures that the deliverable meets all client specifications. At each step, traceability and accountability must be preserved.
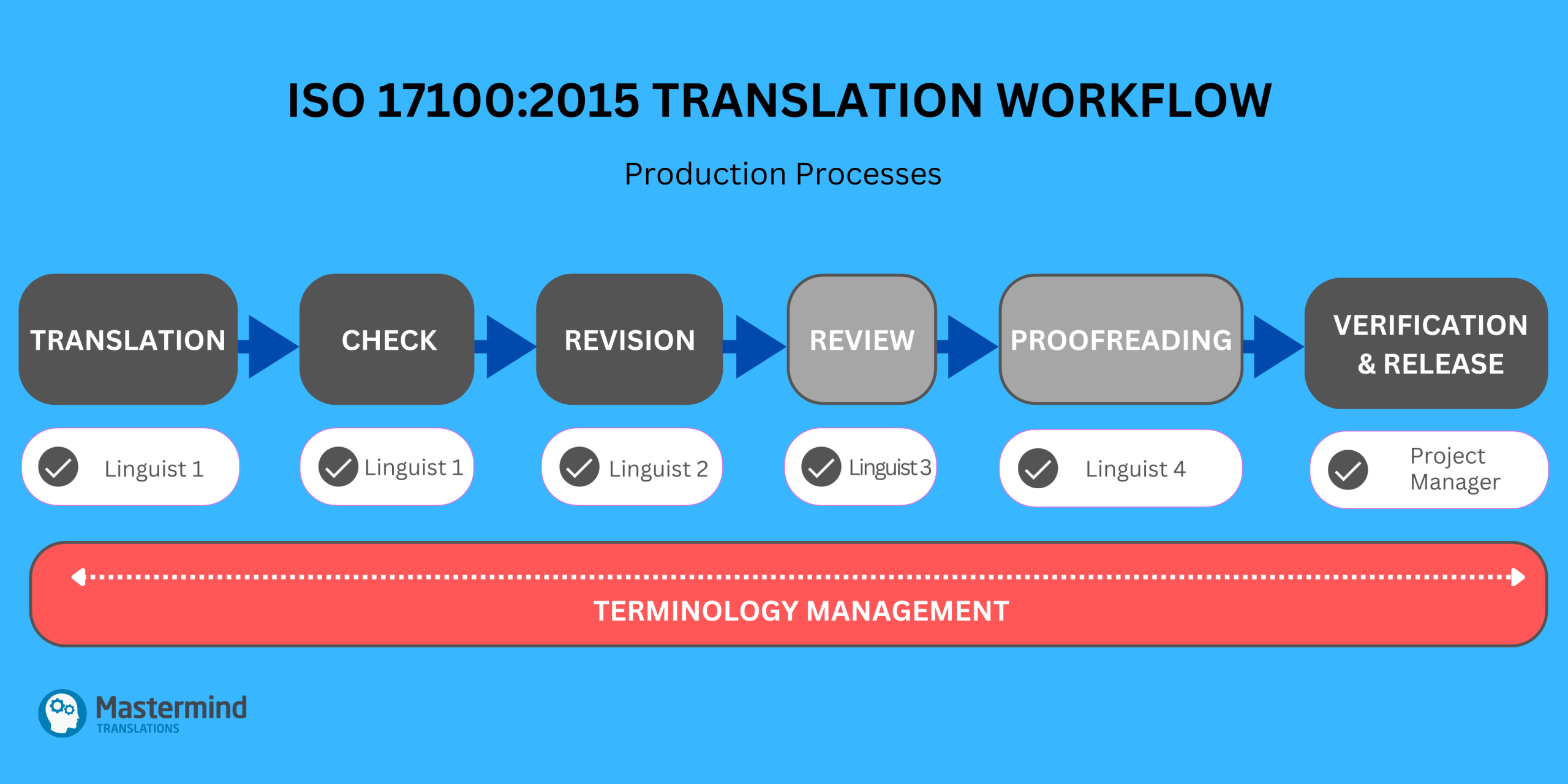
While the standard allows linguists to use LLM and NMT tools to support their work, it is explicit that such technologies may be used only as an aid to the human translator, not a substitute. The human translator remains fully responsible for ensuring that the text meets all quality requirements, including semantic accuracy, domain-appropriate terminology, and compliance with formatting and phrasing conventions (e.g. regulators’ templates). Importantly, raw LLM or NMT output that is only post-edited does not meet ISO 17100 requirements, as it bypasses the core process of independently performed human translation and revision. Such workflows fall under ISO 18587, which governs the post-editing of machine translation (MTPE) output, and is not suitable for high-risk or regulated content.
Although it may seem counterintuitive, translation is actually only one part of a compliant translation project lifecycle. In regulated life science contexts, much of the value lies in the coordination of human experts across multiple stages of revision, review, verification, and terminology management. ISO 17100 certification ensures that each of these steps is competently performed and documented — a level of quality assurance that automated tools alone cannot provide.
The Future of AI-Powered Translation in the Life Sciences Sector
As the industry matures beyond the initial hype, it is becoming increasingly clear that the future of language services in life sciences lies not in automation alone, but in intelligent human–AI integration. As with many emerging technologies, AI in translation is following a familiar trajectory identified by the Gartner Hype Cycle: initial excitement and inflated expectations are inevitably tempered by practical limitations before the technology matures into a stable, productive role. The translation industry is now entering this more realistic phase — one that acknowledges both the capabilities and the limitations of AI.
When used appropriately, AI-driven technologies, such as NMT and LLMs, offer powerful support at the translation stage — improving throughput and freeing up human linguists to focus on high-value decision-making. However, in regulated environments, stand-alone AI output remains insufficient. Direct human involvement is essential for ensuring semantic precision, compliance with templates, consistency of terminology, and contextual appropriateness. Maintaining traceability, auditability, and accountability requires qualified human professionals at every stage of the process that will stand up to regulatory scrutiny.
This need for balanced integration is also reflected in the ongoing revision of ISO 17100. The updated version is expected to better align with today’s technological landscape by clarifying how AI-powered tools can be incorporated into translation project lifecycles, while preserving the core requirements for human-led quality assurance — reinforcing the principle that AI should enhance, not replace, human judgement.
As the industry evolves, the focus must remain on delivering translations that are not only fast and cost-effective, but first and foremost accurate, compliant, and risk-proof.